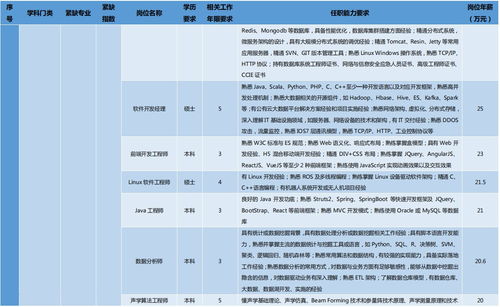
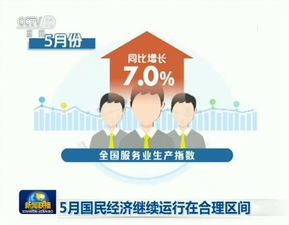
緯創(chuàng)信息技術(shù)服務 以創(chuàng)新技術(shù)驅(qū)動數(shù)字化轉(zhuǎn)型與智能未來
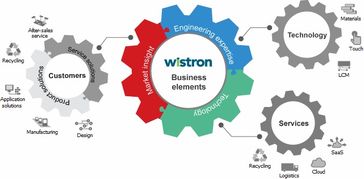
在數(shù)字經(jīng)濟浪潮席卷全球的今天,信息技術(shù)服務已成為企業(yè)提升核心競爭力、實現(xiàn)可持續(xù)發(fā)展的關(guān)鍵引擎。緯創(chuàng)資通(Wistron Corporation),作為全球領(lǐng)先的科技服務提供商,憑借其深厚的技術(shù)積累、全球化的服務網(wǎng)絡以及對行業(yè)趨勢的前瞻洞察,正以其全面的信息技術(shù)服務解決方案,賦能千行百業(yè)的數(shù)字化轉(zhuǎn)型與智能化升級。
緯創(chuàng)的信息技術(shù)服務版圖廣闊而深入,核心優(yōu)勢體現(xiàn)在以下幾個層面:
一、全方位、全周期的數(shù)字化解決方案
緯創(chuàng)不僅提供傳統(tǒng)的IT基礎設施搭建與運維服務,更致力于成為客戶數(shù)字化轉(zhuǎn)型的全周期伙伴。服務范圍涵蓋:
- 云計算與數(shù)據(jù)中心服務:提供從規(guī)劃、部署、遷移到優(yōu)化管理的全棧云服務,幫助企業(yè)構(gòu)建高效、彈性、安全的混合云或多云環(huán)境。
- 企業(yè)應用與軟件服務:包括ERP、CRM等核心業(yè)務系統(tǒng)的實施、定制開發(fā)、集成與優(yōu)化,助力企業(yè)流程再造與運營效率提升。
- 網(wǎng)絡與通信解決方案:設計和部署安全、可靠的網(wǎng)絡架構(gòu),支持5G、SD-WAN等前沿技術(shù)應用,保障企業(yè)通信暢通與數(shù)據(jù)流轉(zhuǎn)。
- 端到端的IT運維與管理(ITSM):通過智能化的監(jiān)控平臺和專業(yè)的服務團隊,提供7x24小時的主動式運維,確保系統(tǒng)穩(wěn)定與業(yè)務連續(xù)性。
二、聚焦前沿技術(shù)的創(chuàng)新賦能
緯創(chuàng)積極投入研發(fā),將人工智能(AI)、物聯(lián)網(wǎng)(IoT)、大數(shù)據(jù)、邊緣計算等前沿技術(shù)深度融入服務體系:
- AI賦能智能決策:通過AI算法與機器學習模型,為客戶提供智能數(shù)據(jù)分析、預測性維護、自動化流程等解決方案,驅(qū)動業(yè)務決策從“經(jīng)驗驅(qū)動”轉(zhuǎn)向“數(shù)據(jù)驅(qū)動”。
- IoT連接萬物智聯(lián):在智能制造、智慧城市、智慧醫(yī)療等領(lǐng)域,提供從感知層設備、網(wǎng)絡連接、平臺搭建到應用開發(fā)的一體化IoT服務,實現(xiàn)物理世界與數(shù)字世界的深度融合。
- 大數(shù)據(jù)挖掘價值:幫助企業(yè)構(gòu)建數(shù)據(jù)湖、數(shù)據(jù)中臺,挖掘海量數(shù)據(jù)背后的商業(yè)洞察,釋放數(shù)據(jù)資產(chǎn)價值。
三、深厚的行業(yè)知識與全球化交付能力
緯創(chuàng)深耕制造、金融、醫(yī)療、零售、電信等多個關(guān)鍵行業(yè),積累了豐富的行業(yè)知識(Know-How)與最佳實踐。這使得其解決方案能緊密貼合特定行業(yè)的業(yè)務流程與監(jiān)管要求,提供高度定制化的服務。依托其全球化的布局與交付中心,緯創(chuàng)能為跨國企業(yè)提供一致、高質(zhì)量、符合當?shù)匾?guī)范的信息技術(shù)服務,支持其全球業(yè)務拓展。
四、安全可信的基石
在網(wǎng)絡安全威脅日益復雜的背景下,緯創(chuàng)將安全視為生命線。其服務貫穿“安全左移”理念,從解決方案的設計階段即融入安全考量,提供包括網(wǎng)絡安全架構(gòu)設計、身份與訪問管理、數(shù)據(jù)加密、威脅檢測與響應、合規(guī)咨詢等全面的網(wǎng)絡安全服務,為客戶構(gòu)建縱深防御體系,保障數(shù)字資產(chǎn)安全。
五、面向未來的協(xié)同共創(chuàng)模式
緯創(chuàng)倡導與客戶、合作伙伴的開放協(xié)作。通過建立聯(lián)合創(chuàng)新實驗室、開展技術(shù)共研、構(gòu)建開發(fā)者生態(tài)等方式,與生態(tài)伙伴共同探索新技術(shù)場景下的商業(yè)模式與解決方案,加速創(chuàng)新落地,共贏智能未來。
****
總而言之,緯創(chuàng)信息技術(shù)服務已超越傳統(tǒng)IT支持的范疇,演變?yōu)橐约夹g(shù)為驅(qū)動、以業(yè)務價值為導向的戰(zhàn)略性服務。它正通過整合先進技術(shù)、行業(yè)智慧與全球化運營能力,為企業(yè)和組織鋪設通往數(shù)字化、智能化未來的堅實橋梁。在充滿不確定性的時代,選擇緯創(chuàng)這樣的合作伙伴,意味著選擇了持續(xù)創(chuàng)新的技術(shù)后盾、穩(wěn)健可靠的運營保障以及前瞻未來的成長視野。
最新產(chǎn)品